Introduction to CovVise
Written by Robert Woods-Corwin, and Wilson Snyder <wsnyder@wsnyder.org>.
CovVise is no longer being used nor supported.
CovVise wasn an open-sourced verification coverage database system that handled billions of events per day, optionally under the BugVise or SystemPerl systems.
Feature Summary
CovVise was a unique coverage system in these ways:
- CovVise can handle 100,000 plus bins (coverage points) per test.
- CovVise can handle 100,000 plus test runs per day, per database server.
- CovVise not only tracks passing tests, but can identify bins which were only hit by failing tests - extremely interesting points to test further.
- CovVise identifies bins that were hit only once or twice in a test; possibly only due to reset transitions.
- CovVise uses hashed objects for all data structures, so that data can be automatically moved between databases. This allows load sharing between multiple coverage database servers. For example, the regression system may populate multiple collection database servers, which in turn feed a master production database. The production database is then age-purged to an archival database. This allows scaling to millions of tests per day.
Papers and Presentations
CovVise was presented by Wilson Snyder <wsnyder@wsnyder.org> at the 2009 Boston Synopsys User's Group. See the papers links.
CovVise: How We Stopped Throwing Away Coverage Data: Paper (.pdf)
CovVise: How We Stopped Throwing Away Coverage Data: Presentation Slides (.pdf)
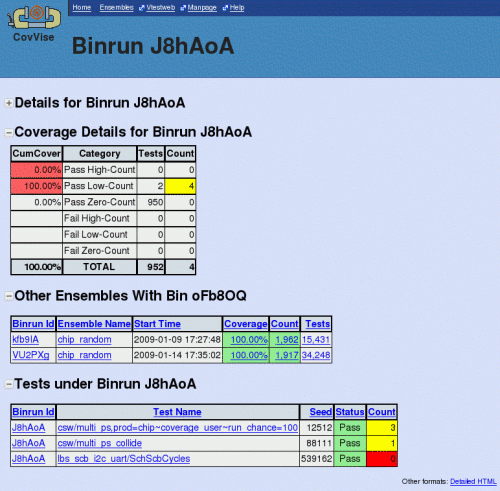
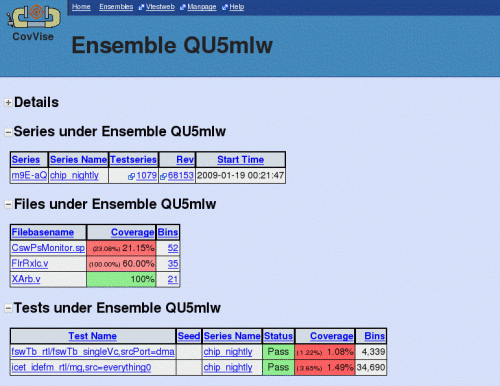
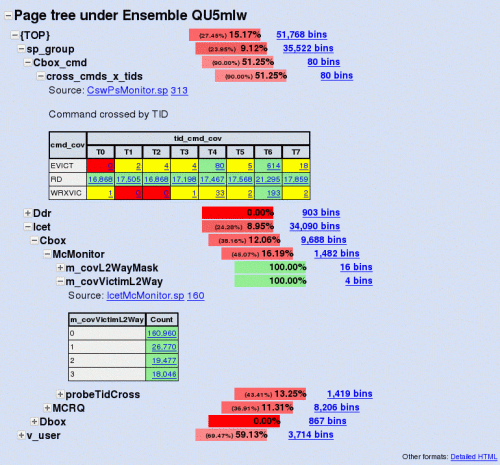
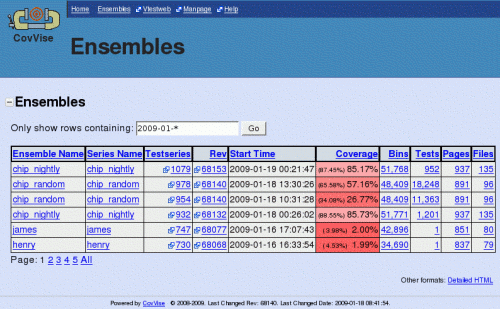
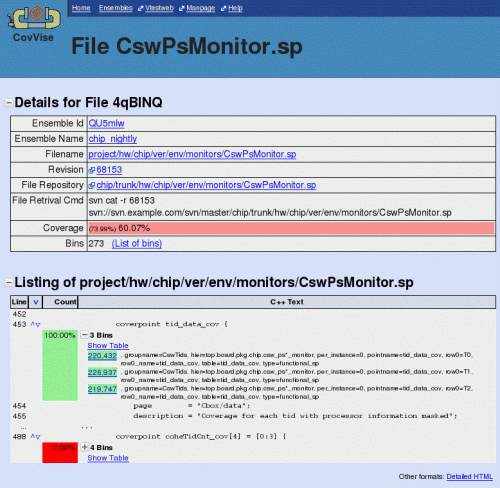
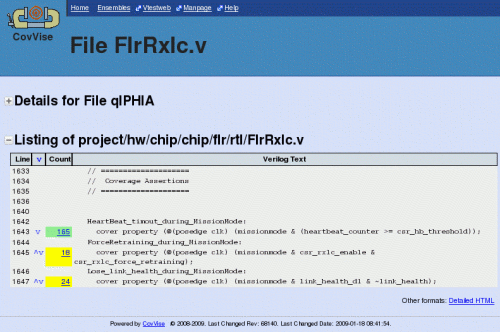
Screenshots